우선 제작하기 전에 어떤 식으로 데이터 시각화를 할지 생각해봤다. 생각해본 구성은 다음과 같다
- 긍정적인 문장과 부정적인 문장을 보여준다
- 긍정적인 문장의 수와 부정적인 문장의 수를 카운팅 하는 시각화를 보여준다
- 긍정적인 문장에서의 word cloud와 부정적인 문장에서의 word cloud를 보여주면서 각각의 키워드를 눈에 잘 보이게 한다
위와 같은 구성으로 시각화를 한 순서를 포스팅해보려 한다
1. 긍부정 문장 데이터 테이블 생성
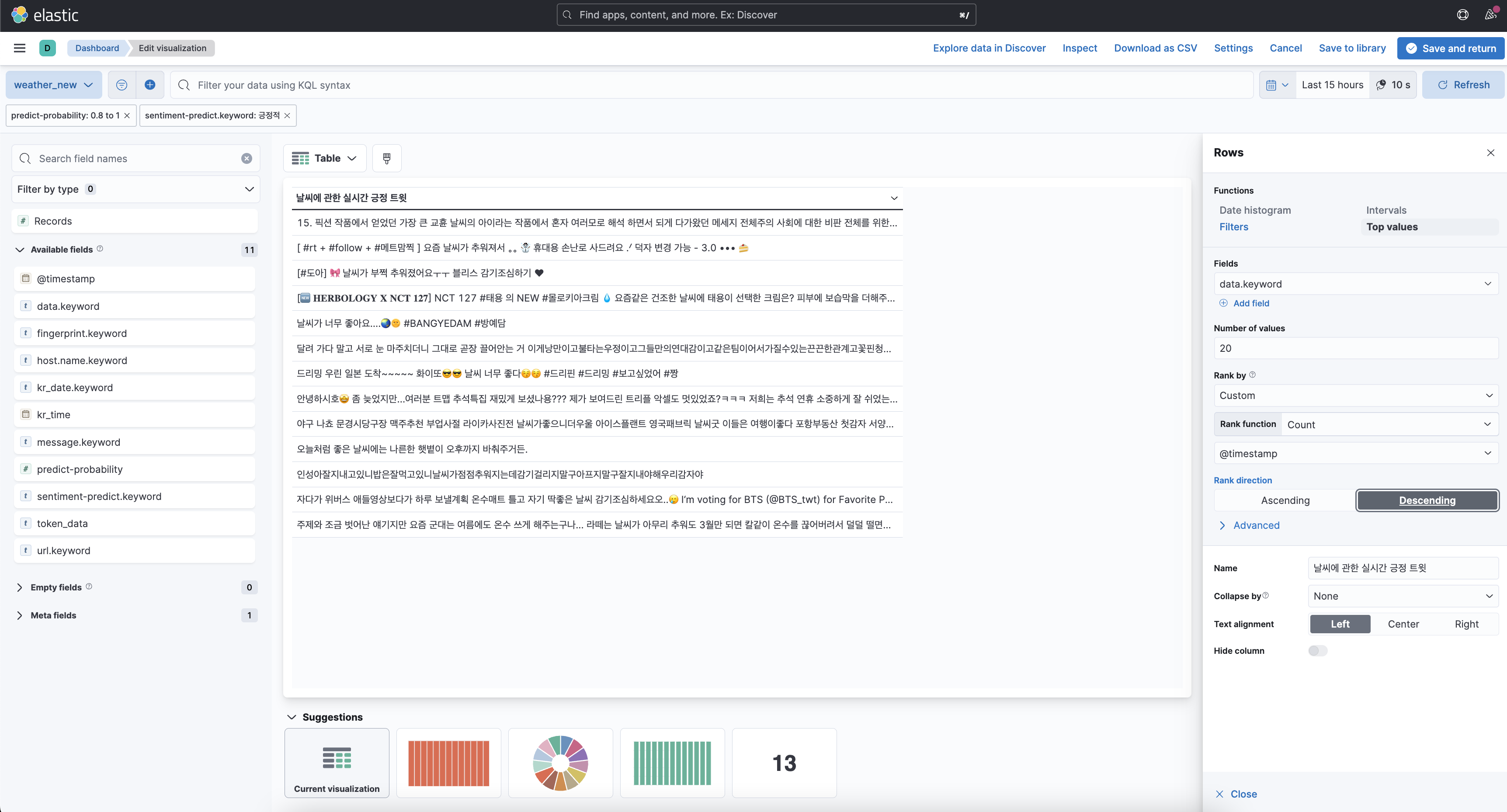
우선 긍정적인 문장과 부정적인 문장을 보여주기 위해서 data table 시각화를 사용하였고 필터는 앞서 Ingest pipeline에서 긍정, 부정으로 나눈 결과를 사용하였다. 여기서 시각화 조건을 보면 predict-probability가 0.8에서 1로 설정해주었고 감정분석 결과가 긍정적인 것만 시각화 되게 설정했다. 여기서 처음에 예측 정확도가 너무 떨어지는 것들은 추가하지 않기 위해서 이렇게 설정했다. 이 설정을 하려면 predict-probability가 소수여야 하는데 기존 pipeline을 실행시키면 text타입으로 저장되었기에 ingest pipeline에 convert 부분을 추가시켜 형 변환을 시켜준 후 시각화하였다.
2. Gauge 시각화
앞서서 데이터 테이블에 대한 시각화를 했고 이제 각각 긍정 부정이 몇 개씩 있는지를 게이지화 시켜서 보여주는 시각화를 하려고 했고 필터 구성은 다음과 같다.
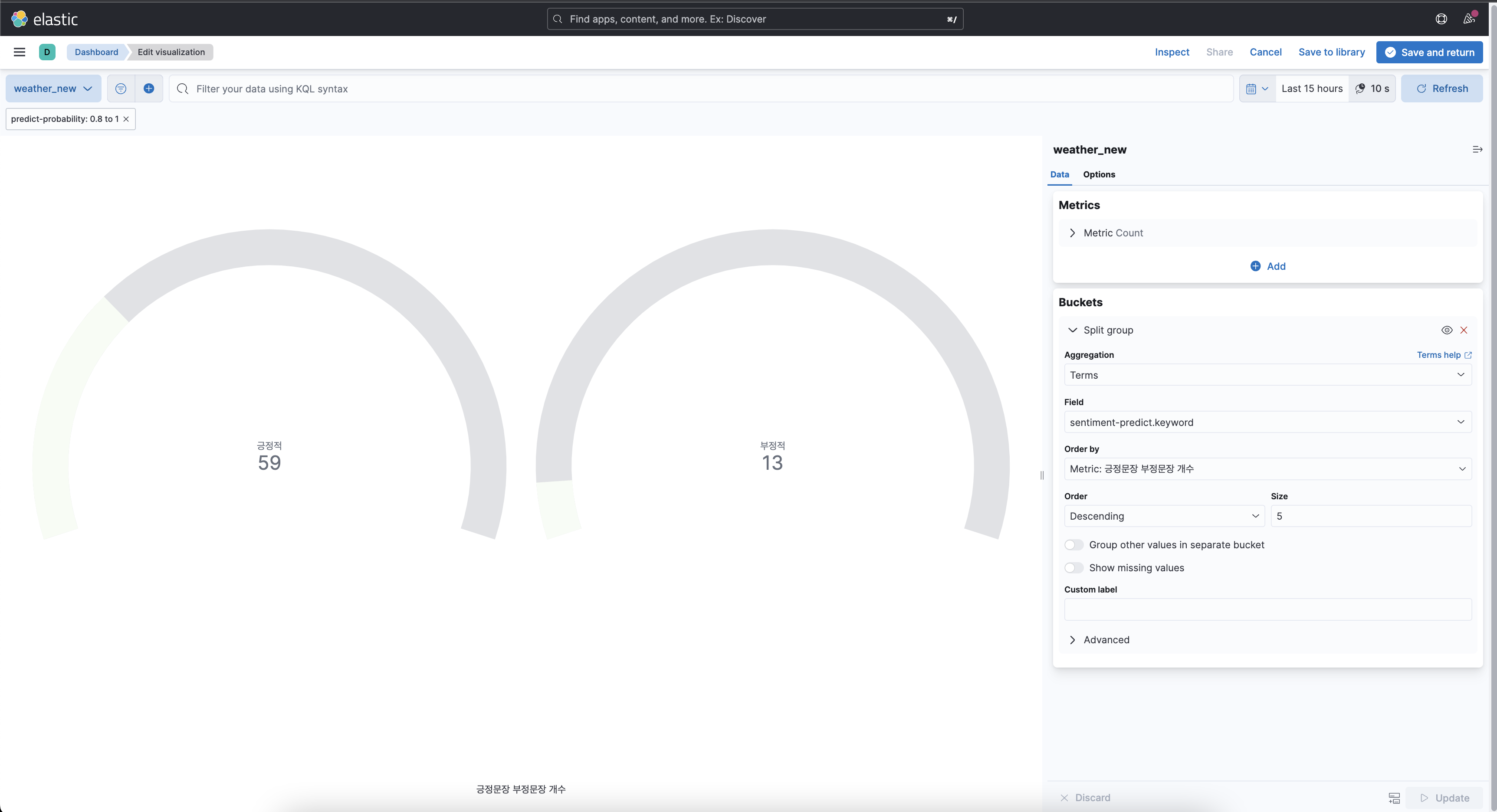
구성에 대해서 간단하게 설명해보면 앞서 긍정, 부정을 예측해서 나타낸 필드인 setiment-predict의 긍정적, 부정적 개수를 따로 집계하여 서로 비교할 수 있도록 하였다. 여기서도 똑같이 정확도가 떨어지는 텍스트는 제외하기 위해서 0.8-1 사이의 정확도를 가진 텍스트만 집계하였다
3. 긍정, 부정 Word Cloud
word cloud를 구성하는데 상당한 시간이 걸렸다. 처음에는 단순히 그냥 data필드로 시각화하면 될 줄 알았었다. 하지만 다음과 같은 문제가 발생했다.

위의 사진과 같이 data 필드에 있는 문장이 word cloud형식이 아닌 문장 전체로 집계가 되어서 표시되는 현상이 발생했다.. 하지만 나는 이유를 몰랐었고 문제점을 찾아서 정상적으로 만드는 것에만 1일을 투자한 것 같다. 여기서 발생한 문제는 아래와 같다
- data field의 옵션인 fielddata가 true로 설정되어 있지 않아서 정상적으로 분리가 되지 않았음
- 이대로 그냥 분리했을 때 불용어가 같이 들어가게 되어서 정상적인 시각화라고 할 수 없음.
- data field의 옵션인 fielddata를 true로 설정하게 되면 data table로 시각화했던 부분이 단어 단위로 끊어져서 시각화돼버림
*해결방안
- data 필드를 복사한 token_data 필드를 새로 생성해서 이 필드를 fielddata:true로 만든다.
- nori tokenizer를 token_data 필드에 적용시켜 불용어를 제거시킨다.
- 날짜 별로 인덱스를 다르게 할 예정이었기 때문에 template를 만들어서 적용시킨다.
*nori 플러그인 다운
우선 Elastic search에서 nori tokenizer을 사용하기 위해서는 플러그인을 다운로드하여야 한다. 다운 방법은 docker 터미널 환경에서 bin/elasticsearch-plugin install analysis-nori 명령어를 실행시키면 된다.

이미지에서 실패한 이유는 이 포스팅을 쓰기 전에 미리 다운을 받았었기 때문에 에러가 발생한 것이고 실제로 처음 실행 시에는 정상적으로 작동했다.
* Logstash에서 Elasticsearch template으로 output
#weather.json
{
"index_patterns": ["weather-*"],
"template":{
"settings" : {
"index.refresh_interval" : "5s",
"analysis" : {
"tokenizer":{
"korean_nori":{
"type": "nori_tokenizer",
"decompound_mode":"mixed"
}
},
"analyzer" : {
"nori_analyzer" : {
"type" : "custom",
"tokenizer":"korean_nori",
"filter":[
"nori_posfilter"
]
}
},
"filter":{
"nori_posfilter":{
"type":"nori_part_of_speech",
"stoptags":[
"E",
"IC",
"J",
"MAG",
"MAJ",
"MM",
"SP",
"SSC",
"SSO",
"SC",
"SE",
"XPN",
"XSA",
"XSN",
"XSV",
"UNA",
"NA",
"VSV",
"SF",
"VA",
"VCN",
"VCP",
"VX",
"VV",
"NR",
"XR",
"NP",
"SN",
"NNB"
]
}
}
}
},
"mappings" : {
"properties" : {
"token_data":{
"type":"text",
"analyzer": "nori_analyzer",
"fielddata":true
}
}
}
}
}위의 템플릿에 대해서 설명하면 인덱스 패턴은 weather-*로 설정해주었고 setting에서 tokenizer를 nori로 설정함과 동시에 불용어를 제거시켜주기 위해서 stoptags를 포함한 커스텀 tokenizer를 만들어서 적용시켜주었다. 또한 token_data 필드는 텍스트 타입이어야 분리시킬 수 있으므로 텍스트 타입으로 하였고 analyzer를 만든 tokenizer로 설정해주며 fileddata:true를 설정하여 단어별로 분리시키는 필드로 매핑했다.
#logstash pipeline 수정사항
filter{
grok{ #token_data 필드 생성
match => {"data" => "%{GREEDYDATA:token_data}"}
}
}
output {
elasticsearch { #템플릿파일 경로에 있는 템플릿 생성하여 데이터를 output
template => "/usr/share/logstash/templates/weather.json"
template_name => "weather"
}
}앞서 만들었던 logstash pipeline에서 수정된 부분만 위의 코드 블록에 적었다.
*word cloud 시각화 필터
이제 앞서서 모든 것들을 처리했으니 워드 클라우드를 생성해 보려고 한다.
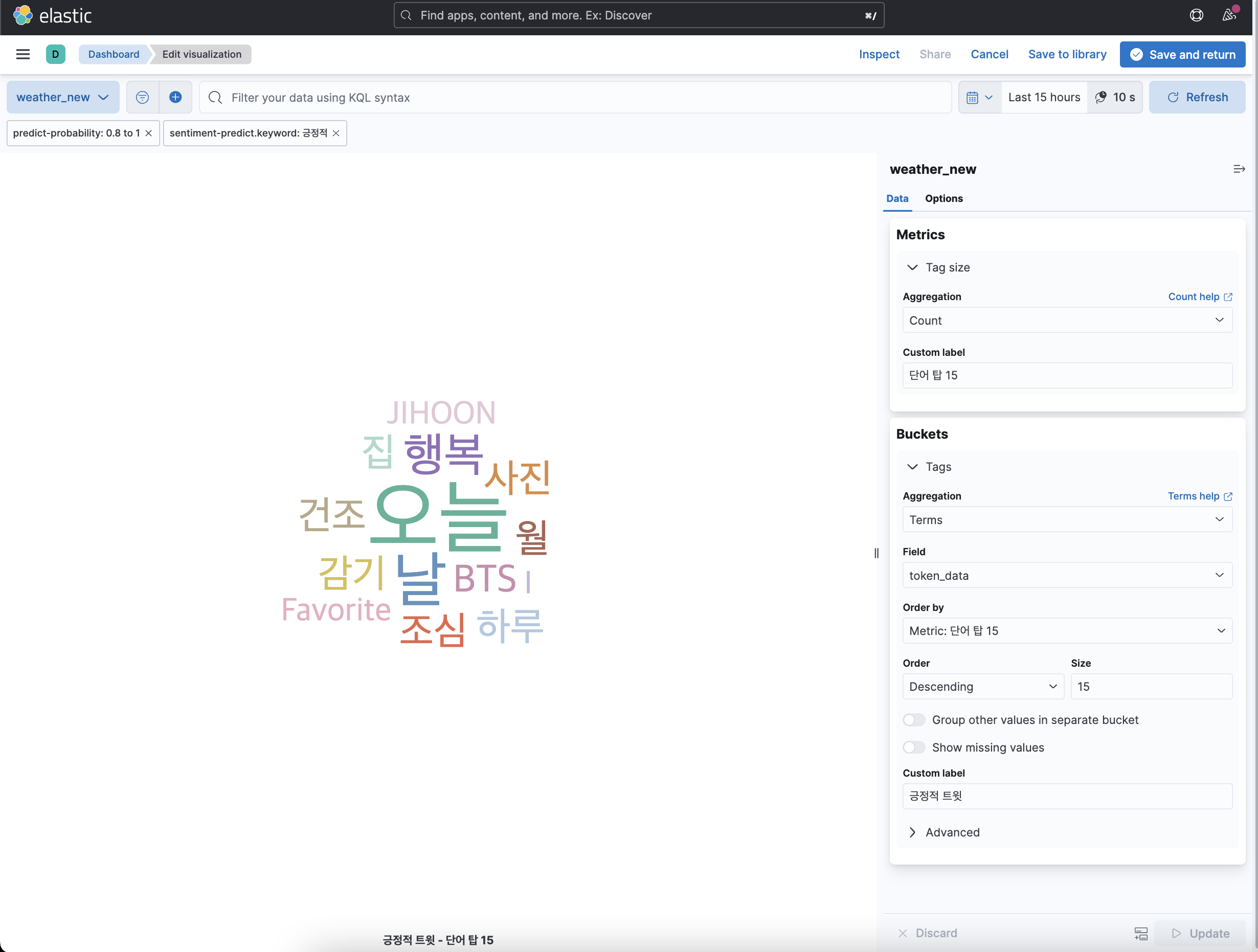
여기서 보면은 앞서 시각화한 것과 동일하게 정확도를 0.8~1로 설정해주었고 긍정적 트윗 워드 클라우드만을 시각화하기 위해서 필터를 긍정적으로 정했으며 많이 언급된 단어를 탑 15까지 워드 클라우드로 표현해주게 설정하였다. 부정적 워드 클라우드도 예측 필터가 부정적인 것을 제외하고는 동일하게 설정하였다.
4. 마무리
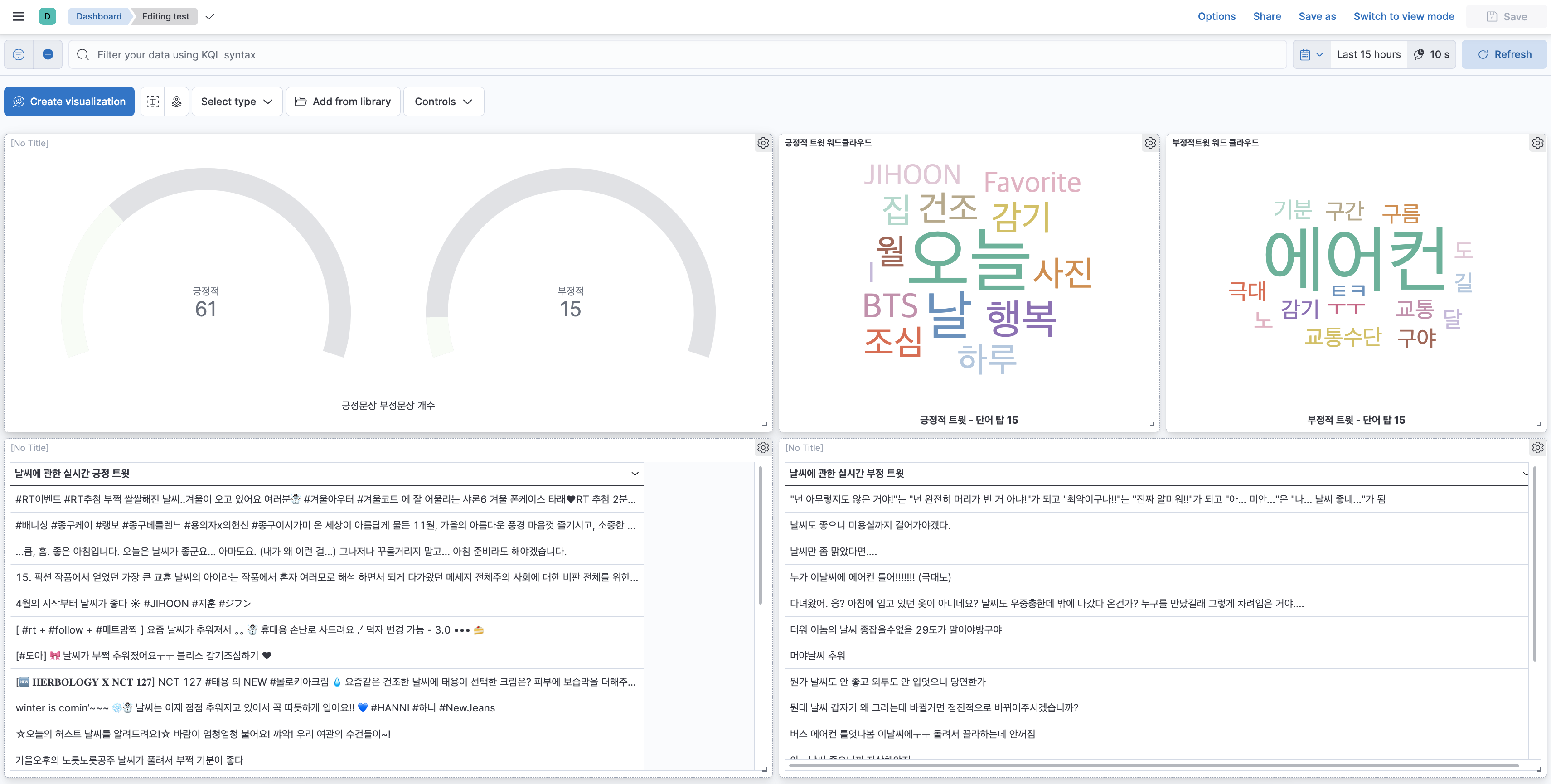
이렇게 해서 대시보드를 완성시켰고 나름 나의 첫 프로젝트를 성공적으로 마무리한 것 같다. 이 대시보드를 export 하려고 했으나 m1 mac에서 내보내기를 할 때 오류가 발생하여서 하지 못한 게 너무 아쉽지만 그래도 완성시켜서 너무 뿌듯하다. 이 프로젝트를 진행하면서 아쉬웠던 점, 알아간 점, 오류가 발생했던 부분들은 다음 포스팅에 정리해보려고 한다. 다음번에는 kubernetes로 한번 환경을 구축해서 도전해봐야겠다!
'개인프로젝트 > twitter 실시간 데이터 프로젝트(ELK stack)' 카테고리의 다른 글
| 실시간 데이터 프로젝트 회고 (1) | 2022.11.10 |
|---|---|
| 데이터 감정분석 파이프라인 구축 (0) | 2022.11.03 |
| Logstash 실시간 데이터 처리 (0) | 2022.10.29 |
| twitter 실시간 데이터 python으로 저장하기 (0) | 2022.10.21 |
| [docker] python+filebeat+elk 환경 만들기 (0) | 2022.10.17 |